
山田工業社員の目から見た日常をお伝えします。
| ← | 2026年7月 | → | |||||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 | |
| 1 | 2 | 3 | 4 | ||||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 | |
| 19 | 20 | 21 | 22 | 23 | 24 |
|
|
| 26 | 27 | 28 | 29 | 30 | 31 | ||
| 最近の記事 |
| 令和丙午8年新秩父観音霊場ご開 ..
|
| くずし字が簡単に読めるかも |
| 凸版印刷株式会社が「くずし字を判別してテキストデータ化するOCR(光学文字認識)技術」を開発したと発表しました。 凸版印刷(株)では、この技術による古典籍のテキストデータ化サービスを2015年夏から試験的に開始するそうです。 江戸期以前の本や明治期の手書きの文章の多くは「くずし字」を使って書かれており、楷書で読み書きを教えられた昭和特に戦後生まれの人では読めない人がほとんどです。 くずし字の学習は近世以前の日本文学や日本史を学ぶ学生にとっては必要不可欠で、多くの学生が「よ、読めない……」と悲鳴を上げているそうですが、遊んでるんだか、バイトしに行ってるんだか、およそ学生とは名ばかりの学生には当然だと思います。 しかし、凸版印刷の開発した技術は、書物のくずし字を自動で判読し、テキストデータ化することを可能にするもので、専門の学習をしていない素人にも読めるかもしれない朗報です。 凸版印刷で2014年に実施した検証実験では、くずし字で記されている書物を80%以上の精度でOCR処理することができたとのこと。 OCRで判読した文字は更に専門家によって校正・校閲され、その結果はくずし字のデータベースにフィードバックされます。  「源氏物語」(絵入本,国文研所蔵)のOCRによるテキストデータ化の例 現在、くずし字で書かれている古典籍は100万点以上と言われていて、大部分が翻刻(ほんこく、くずし字で書かれた文献を楷書に直したり活字で出版するなどして読みやすい形式にすること)されていません。 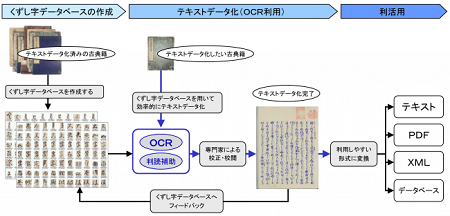 この技術が広まれば、専門の翻訳家に頼らないでもくずし字を訳せるので、安く、また大量にデータ化することも可能です。 自分の持っている明治期の千社札や、納札に関する資料も読めるようになればいいな〜。 |
17:45, Wednesday, Jul 08, 2015 ¦ 固定リンク
■コメント
| 最近のコメント |
| 最近のトラックバック |
| 携帯で読む |